API Reference
Introduction
PrintNode exposes its functionality through an HTTPS API. This API is used for printing, querying data (including scale data) and account management.
Before using the PrintNode API, you will need to sign up for a PrintNode account. Signing up is free and carries no obligations.
All API requests must be authenticated. The easiest way to get started is to generate an API Key and use it to authenticate your API requests.
If you have any questions or concerns, want some help or see anything unexpected, please contact us.
API Endpoint
The base URL for the API is:
https://api.printnode.com
Where relative URLs appear in this documentation, they are relative to this base URL.
Overview
Authentication
All requests must be authenticated using HTTP basic authentication. API Keys are links to a single account and are used for both authentication and identification. Any API Key attached to your account will work. You can have as many API Keys as you wish.
Submitting the API Key as the username and leaving the password empty will authenticate you.
You can view and create API Keys here.
An example cURL request might look like this:
cURL uses the -u flag to transmit basic auth credentials. Note the colon at the end of the username string. This is not part of your API Key – it just indicates the end of the username part of cURL's credentials argument.
Successful authentication
Requests which successfully authenticate have the
header X-Account set.
Unsuccessful authentication
Requests which are unsuccessful will return HTTP 401 Unauthorized.
Content Types
You can POST data using
either: Content-Type: application/json
or Content-Type: application/x-www-form-urlencoded.
The key-value structure for both types is the same.
If you don't specify a Content-Type
then Content-Type: application/json will
be assumed. In either case the PrintNode API will always respond with
Content-Type: application/json.
Parameters
PrintNode assigns a unique identifier to computers, printers and other assets it is aware of. A unique identifier is always a positive integer. A set is a string representation of an unordered collection of positive integers. You can use these to specify multiple assets in a single API call.
Wherever you see COMPUTER SET, PRINTER SET or PRINT JOB SET you can substitute a set.
A set is written as a comma separated list of positive integers. Repeated integers are only counted once.
Examples
1 | 1 |
1,3,5 | 1, 3 and 5 |
5,1,3 | 1, 3 and 5 |
1,2,2,3,3,3 | 1, 2 and 3 |
Resource URLs
GET/whoami
GET/computers
DELETE/computers
GET/computers/COMPUTER SET
DELETE/computers/COMPUTER SET
GET/printers
GET/printers/PRINTER SET
GET/computers/COMPUTER SET/printers
GET/computers/COMPUTER SET/printers/PRINTER SET
GET/printjobs
DELETE/printjobs
POST/printjobs
GET/printjobs/PRINT JOB SET
DELETE/printjobs/PRINT JOB SET
GET/printers/PRINTER SET/printjobs
DELETE/printers/PRINTER SET/printjobs
GET/printers/PRINTER SET/printjobs/PRINT JOB SET
DELETE/printers/PRINTER SET/printjobs/PRINT JOB SET
GET/printjobs/states
GET/printjobs/PRINT JOB SET/states
GET/computer/COMPUTER ID/scales
GET/computer/COMPUTER ID/scales/DEVICE NAME
GET/computer/COMPUTER ID/scale/DEVICE NAME/DEVICE NUMBER
PUT/scale
DELETE/account
POST/account
PATCH/account
GET/account/state
PUT/account/state
GET/account/tag/NAME
DELETE/account/tag/NAME
POST/account/tag/NAME
GET/account/apikey/DESCRIPTION
DELETE/account/apikey/DESCRIPTION
POST/account/apikey/DESCRIPTION
GET/account/controllable
GET/download/client/OPERATING SYSTEM
GET/download/clients
GET/download/clients/DOWNLOAD IDS
PATCH/download/clients/DOWNLOAD IDS
GET/ping
GET/noop
Pagination
By default, endpoints which return a set of records
(such as GET/computers or GET/printjobs)
will return up to 100 records, in descending id order, which is equivalent to the most recent 100 records.
You can control the range of records returned using the URL query parameters limit, after and dir.
They work as follows:
limitis the maximum number of rows that will be returned by the endpoint. Default is 100.dircontrols the ordering -ascfor ascending,descfor descending. Default isdesc.aftercontrols the point at which records start. You would usually set this to the last id in the previous set of records retrieved, in order to look at the next "page" of records. Default is blank, which causes records to be retrieved at one end of the result set (the start ifdirisascand the end ifdirisdesc).
For example:
- Leaving all parameters unspecified returns (up to) 100 records, starting from the highest available (i.e. most recent) id, in descending order.
dir=ascreturns (up to) 100 records, this time starting from the lowest id, in ascending order.after=123&limit=50returns (up to) 50 records, starting from the record below id 123, in descending order.after=123456&dir=asc&limit=20returns (up to) 20 records, starting from the record after id 123456, in ascending order.
Example Request cURL
This returns (up to) 20 print jobs, starting from the record after id 123456, in ascending order.
Response Headers
The server responds with standard HTTP response headers and some or all of the following extra headers depending on the endpoint you are querying:
Request-Id |
A unique identifier for your request. This is useful if you want to report an API issue to us; it allows us to find the request in our server logs. |
Elapsed |
The time the server took to handle the request, in seconds. |
Access-Control-Allow-OriginAccess-Control-Allow-HeadersAccess-Control-Allow-MethodsAccess-Control-Expose-Headers |
HTTP access control headers. |
Rate Limiting
The API allows 10 requests per second per account.
Short bursts of requests which exceed this limit are also permitted.
Exceeding the limit for a sustained period will result in some requests
returning HTTP 429 Too Many Requests.
Example Response
Errors
The API returns self documenting, human-readable errors.
When an error occurs, the response body is a JSON object containing three keys:
uid, code and message. uid has the same value as the Request-Id response header, code is a brief textual description of the error and
message is a detailed human-readable
description of the error.
These error messages are very useful! If your API request is not functioning as expected, the response body is the first place you should look.
Example Errors
Account Information
Who Am I?
GET/whoami
Example Request cURL
Response
Computers
Viewing Computers
GET/computers
GET/computers/COMPUTER SET
Computers are devices which have the PrintNode Client
software installed on them and which have successfully connected
to PrintNode. A computer is uniquely identified by its id property.
When the PrintNode Client runs on a computer it automatically reports
the existence of the computer to the server. From then on the computer is recognized
by the API.
Example Request cURL
Response
Removing Computers
DELETE/computers
DELETE/computers/COMPUTER SET
You can remove computers with a call to the above endpoints.
You can restrict the set of computers you wish to delete by specifying
a computer set. The server will respond HTTP 200 OK
and the response body will be a JSON array of the ids of the computers
which have been affected.
Example Request cURL
Response
Printers
Viewing Printers
GET/printers
GET/printers/PRINTER SET
GET/computers/COMPUTER SET/printers
GET/computers/COMPUTER SET/printers/PRINTER SET
Example Request cURL
Response
Printer Capabilities
Most printers support various options to customise printing, such as choosing a paper tray, choosing a media size, setting number of copies, duplex printing, etc.
The capabilities property of the printer object tells you what printing options you can use when creating a print job.
| Attribute | Type | Description |
|---|---|---|
| bins | Array of strings | A array of paper tray names the printer driver supports. May be zero length. |
| collate | Boolean | true if the printer supports collation;
false otherwise. |
| copies | Integer | The maximum number of copies this printer supports.
If the printer does not support multiple copies this value
will be 1. |
| color | Boolean | true if the printer is a colour printer;
false otherwise. |
| dpis | Array of strings | An array of strings, each of which describes a dpi setting supported by the printer. May be zero length. |
| extent | Array of arrays | If the printer driver reports its maximum and minimum
supported paper sizes, this is a two-dimensional
array of integers, where [0][0] and [0][1] are respectively the minimum
supported width and height and [1][0] and [1][1]
are respectively the maximum supported width and height. The units
are tenths of a millimetre. If the printer driver does not report this information, this is a zero-length array. |
| medias | Array of strings | An array of media names the printer driver supports. May be zero length. |
| nup | Array of integers | The set of values of N for which N-up printing is supported, or a zero-length array if N-up printing is not supported. |
| papers | Object | Object of supported paper sizes where each key represents
a paper name and the corresponding value is the dimension
of the paper expressed in a two-value array.
The array is expressed as
[width, height] with width and height
expressed in tenths of a millimetre.
In some circumstances these values are not reported
by the printer driver, in which case the array is [null, null]. |
| printrate | Object or null | Object describing the printer's reported print rate.
This object has two keys
– unit and rate.
unit can be one of "ppm", "ipm", "lmp" or "cpm".
rate is a float.If this is not specified by the driver, its value is null. |
| supports_custom_paper_size | Boolean | true if the printer supports custom paper sizes;
false otherwise. |
A sample printer capabilities object is shown below.
Print Jobs
Creating Print Jobs
POST/printjobs
A print job is a request to print a document. You can create a print job using this endpoint.
| Attribute | Type | Is Required? | Specification |
|---|---|---|---|
| printerId | Integer | Yes | The id of the printer you wish to print to. |
| contentType | String | Yes | Either pdf_uri, pdf_base64, raw_uri or raw_base64. See content. |
| content | String | Yes | If contentType is pdf_uri or raw_uri, this should be the URI
from which the document you wish to print can be downloaded.
If contentType
is pdf_base64 or raw_base64, this should be the base64-encoding of the document you wish to print. |
| title | String | No | A title to give the print job. This is the name which will appear in the operating system's print queue. |
| source | String | No | A text description of how the print job was created or where the print job originated. |
| options | Object | No | An object describing various options which can be set for this print job. See options. Printing options have no effect when RAW printing. |
| expireAfter | Integer | No | The maximum number of seconds PrintNode should retain this print job in the event that the print job cannot be printed immediately. The current default is 14 days or 1,209,600 seconds. |
| qty | Integer | No |
A positive integer specifying
the number of times this print job should be delivered to the print queue.
This differs from the copies option in that this will send
the document
to the printer multiple times and does not rely on printer driver support.
This is the only way to produce multiple copies when
RAW printing.
This also allows you to print multiple copies even when
not natively supported by the printer driver.The default value is 1. |
| authentication | Object | No |
If a contentType of pdf_uri or raw_uri is used, the PrintNode Client must download the document
from a location which you specify in the content attribute
before it can print it. If access to this location requires
HTTP Basic or Digest Authentication you can
specify the username and password information here.For Basic authentication: {
"type": "BasicAuth",
"credentials": {
"user": "username",
"pass": "password"
}
}
For Digest authentication: {
"type": "DigestAuth",
"credentials": {
"user": "username",
"pass": "password"
}
}
Replace |
Example Request cURL
Response
Example Request cURL
Response
Print job options
These additional options can be specified
in the options attribute when you create a print job.
Note that very old
versions of the PrintNode Client may not support these options.
We recommend keeping your PrintNode Client version up-to-date.
All properties are optional. You can use
null or {} to represent no printing options.
| Property | Type | Required | Description |
|---|---|---|---|
| bin | String | No |
The name of one of the paper trays or output bins reported by the
printer capability
property bins.
|
| collate | Boolean | No | Enables print copy collation when printing multiple copies. If this option is not specified the printer default is used. |
| color | Boolean | No | Set this to false for grayscale printing.
This option only takes effect on Windows, with the default printing backend of the PrintNode Client
set to Engine6 (you can change the default printing backend using the drop-down list
in the "Printers" tab of the PrintNode Client's GUI).
If this option is not specified the printer default is used. |
| copies | Integer | No |
Positive integer. Default 1. The number of
copies to be printed. Maximum value as reported by the
printer capability
property copies.
|
| dpi | String | No |
The dpi setting to use for this print job. Allowed values are those reported by the
printer capability
property dpis.
|
| duplex | String | No | One of long-edge or short-edge for
two-sided printing along the long-edge (portrait) or the short edge
(landscape) respectively, or one-sided for single-side printing.
If this option is not specified the printer default is used. |
| fit_to_page | Boolean | No | Set this to true to automatically fit
the document to the page. In Windows, this option is only supported
when using the Engine6 printing backend. |
| media | String | No |
The name of the medium to use for this print job.
This must be one of the values reported by the
printer capability
property medias. Some printers
on macOS / OS X
ignore this setting unless the bin (paper tray) option is also set.
|
| nup | Integer | No |
macOS / OS X only. Allows support for printing muliple pages
per physical sheet of paper. Default 1.
This must be one of the values reported by the
printer capability
property nup.
|
| pages | String | No |
A set of pages to print from a PDF. The format is the same
as the one commonly used in print dialogs in applications.
A few examples:1,3 prints pages 1 and 3. -5 prints pages 1 through 5 inclusive. - prints all pages. 1,3- prints all pages except page 2.
|
| paper | String | No |
The name of the paper size to use. This must be one of the keys
in the object returned by the
printer capability
property papers.
|
| rotate | Integer | No |
One of 0, 90, 180
or 270.
This sets the rotation angle of each page in the print – 0
for portrait, 90 for landscape, 180
for inverted portrait and 270 for inverted landscape.
This setting is absolute and not relative. For example, if your PDF document
is in landscape format, setting this option to 90
will leave it unchanged.
We have found that not all printers and printer drivers support this feature to the same degree. For instance, in Windows the 180 and 270
settings are often respectively treated like 0
and 90, i.e. they switch between portrait and landscape
but do not invert the print.
|
Which Content Type is Right for You?
The content attribute of the print job
may be either a
URI to the document or the base64-encoded content of the document.
We take security seriously at PrintNode but we understand that
some organisations are not comfortable sending document contents
to a third party. In this case, we recommend working
with pdf_uri or raw_uri as your
contentType and hosting the document
yourself so that its contents are never sent to PrintNode.
Using pdf_base64 or raw_base64
to send a print job means
that your data will need to be base64-encoded. This is very easy to do
and you don't have to worry about hosting and managing your
own print jobs. If you are sending small PDFs or doing RAW printing,
e.g. courier labels, barcodes or reciepts, then this is a good option to
choose. Note that base64 encoding increases the size of the content by approximately 33%.
If your PrintNode Client can download the content
from a local network
or web server, it may be faster to use the pdf_uri
or raw_uri.
This means that your print job content is never sent to the
PrintNode server. This is usually faster if content is accessible
locally and it can reduce bandwidth requirements for everyone.
In either case, the request body may not be larger than 50MB.
If you attempt to POST a request that is larger than 50MB you will
receive HTTP 413 Request Body Too Large. You can work around this size limit
by using pdf_uri printing.
| URI | Base64 | |
|---|---|---|
| Security | Print jobs can be hosted on your own servers. | Print jobs are sent through PrintNode servers which may be located outside your country. Note: we don't store your documents after they have been printed and we never read them or analyse their contents. |
| Speed | Slightly faster without the slightly increased overhead of base64. If you can serve the printjob contents to your customers locally this will be faster still. | Slower because of the 33% base64 overhead. This will make the biggest difference over a slow internet connection. |
| Developer Work | You have to host the documents that you will be printing through PrintNode. | You don't need to worry about hosting your own documents. |
| Maximum supported document size | Unlimited. | The request body, which includes the base64-encoded document, must not exceed 50MB. This means the maximum document size is just under 37.5MB. |
Responses
When the print job is received, the PrintNode API will add it to the print queue and respond immediately, i.e. the PrintNode API does not wait for the print job to be sent to the specified printer before responding.
If the computer that controls that printer is not connected, the job will be queued and sent to the computer when it reconnects.
The response body to a successfully created print job is the id of the newly created print job.
Sample PDFs
Below are links to some sample PDF files that you can use for testing your printing.
| Filename | Size | Pages | Dimensions (inches) |
|---|---|---|---|
| 4x6_2_up_ol145.pdf | 293.8KB | 1 | 8.5 x 11 |
| 4x6_2_up_on_8x11_avery_5126_or_ol400.pdf | 297.91KB | 1 | 8.5 x 11 |
| 4x6_2_up_on_8x11_with_packing_slip_avery_5127.pdf | 217.21KB | 1 | 8.5 x 11 |
| 4x6_combo_vertical_ol829.pdf | 128.54KB | 1 | 8.5 x 11 |
| 4x6_label_on_8x11_centered_on_letter_paper.pdf | 148.92KB | 1 | 8.5 x 11 |
| a4_10_pages.pdf | 17.74KB | 10 | 3.9 x 6 |
| a4_500_pages.pdf | 406.73KB | 500 | 8.3 x 11.7 |
| a4_portrait.pdf | 30.78KB | 1 | 8.3 x 11.7 |
| a5_portrait.pdf | 30.54KB | 1 | 5.8 x 8.3 |
| fedex_label.pdf | 30.72KB | 1 | 4 x 6 |
| label_3in_x_1in_barcode.pdf | 6.86KB | 1 | 3 x 1 |
| label_4in_x_6in_ups_with_packing.pdf | 216.08KB | 2 | 6 x 4 |
| label_4in_x_6in_ups.pdf | 149.51KB | 1 | 4 x 6 |
| label_4in_x_6in.pdf | 30.53KB | 1 | 4 x 6 |
| label_6in_x_4in.pdf | 30.19KB | 1 | 6 x 4 |
| letter_portrait.pdf | 30.74KB | 1 | 8.5 x 11 |
| test.pdf | 23.86KB | 2 | 3 x 1 |
| ups_label.pdf | 32.33KB | 1 | 4 x 6 |
| multipage.pdf | 17.74KB | 10 | 3.9 x 6 |
Idempotency
PrintNode allows you to specify an idempotency key when creating a print job. This allows you to submit a print job multiple times whilst assuring that PrintNode will only print it once.
A common scenario where this is useful is in case of an unreliable network connection. Suppose you submit a print job but do not receive a response – how do you know if PrintNode received your request or not? If you do not re-send the request, your print may not happen. If you do, you risk performing it twice.
The solution is to specify an idempotency key with each print job. This is simply
a string which you specify using the X-Idempotency-Key HTTP header. When PrintNode receives a
print job with an idempotency key, it makes a note of the key. Subsequent jobs with the same key are rejected with
HTTP status code 409 (conflict). This way, you can resubmit a print job with confidence that it will not be printed again
if PrintNode received it the first time.
Idempotency keys are not retained forever – they can be reused after 24 hours.
Example Request cURL
Response
Viewing Print Jobs
You can view your print job history via
GET/printjobs. You can
also filter returned print jobs by printer or print job id. Just
substitute the appropriate
parameter
into one of the URLs below.
GET/printjobs
GET/printjobs/PRINT JOB SET
GET/printers/PRINTER SET/printjobs
GET/printers/PRINTER SET/printjobs/PRINT JOB SET
Example Request cURL
Response
Cancelling Print Jobs
DELETE/printjobs
DELETE/printjobs/PRINT JOB SET
DELETE/printers/PRINTER SET/printjobs
DELETE/printers/PRINTER SET/printjobs/PRINT JOB SET
If a print job has not yet been delivered to the PrintNode
Client, you can cancel it using these API endpoints.
It is possible to filter
print jobs by printer and/or print job id. Just substitute the
appropriate
parameters
into one of the URLs above. The server will
respond with HTTP 200 OK and the response body will
be a JSON array of the ids of the print jobs which have been cancelled.
Print jobs which have been completed or have been delivered to the PrintNode Client cannot be cancelled.
Example Request cURL
Response
Print Job States
GET/printjobs/states
GET/printjobs/PRINT JOB SET/states
As a print job is handled it progresses through a number
of states – for example, when a print job is created its state
is always new. The states a print job passes through as it is
processed are not fixed and can vary from print job to print job
(for example, most print jobs finish in the done state but
a print job can finish in the error state if something goes wrong).
Because a print job is created through the API and eventually handed over to a PrintNode Client, print job states can be generated on the PrintNode Server (e.g. new) or the Client (e.g. done). This means that the population of states generated by the Client and Server may change over time as new versions of the Client and Server are released. However, it is important that some states are not subject to change, because integrations and end users need to rely on them for diagnosis, reporting and automation.
For this reason, certain states are defined to be stable. This means they are part of PrintNode's stable API and have the same backwards compatibility guarantees as the rest of the API. It is safe for your integration to rely on these states and their semantics. A print job state will only be published in a webhook message if it is a stable state.
The stable print job states are as follows:
| State | Description |
|---|---|
| new | The print job has been registered in the system. |
| sent_to_client | The print job has been sent to the PrintNode Client. |
| done | The print job has been delivered by the PrintNode Client to the operating system's print queue. This means the print is now outside PrintNode's control – it is still possible for the print to fail at this point, e.g. if the printer malfunctions. |
| error | An error was encountered whilst attempting to execute the print. Possible causes include hardware failure, driver issues, incorrect printer setup and connectivity problems. |
| expired | The print job could not be delivered to the PrintNode Client before its expiry time. |
The object which describes a print job state has the following keys:
| Attribute | Type | Description |
|---|---|---|
| printJobId | Integer | The id of the print job this state relates to. |
| state | String | May be one of the "stable" states described above,
i.e. new, sent_to_client,
done, error or expired,
or some other value. |
| message | String | Additional information about the state. |
| data | Object | Reserved for future use. |
| clientVersion | String | If the state was generated by the PrintNode Client,
this is the Client's version; otherwise null. |
| createTimestamp | String | If the state was generated by the PrintNode Client, this is the timestamp at which the state was reported to the PrintNode Server. Otherwise, it is the timestamp at which the PrintNode Server generated the state. |
| age | Integer | The time elapsed, in milliseconds, between
this state's createTimestamp and the createTimestamp
of the print job's new state. |
Example Request cURL
Response
Scales
HTTP REST
GET/computer/COMPUTER ID/scales
GET/computer/COMPUTER ID/scales/DEVICE NAME
GET/computer/COMPUTER ID/scale/DEVICE NAME/DEVICE NUMBER
These endpoints allow you to query the weighing scales attached to a computer.
Note the plural "scales" in the first two endpoints and singular "scale" in the third endpoint.
This is because the first two endpoints can return data for multiple scales
and the third endpoint always queries a specific scale. Because of this, the first two endpoints
always return a list (which may be empty) and the third endpoint returns a scale data object or
HTTP 404 Not Found.
DEVICE NAME is a string which identifies a make and model of scale. By default this is of the form "manufacturer - model" but can be altered in the PrintNode Client to a more descriptive and convenient identifier. Operating systems don't always allow unique identification of USB devices and in the event multiple scales of the same make and model are connected to a computer, they can be distinguished by the integer DEVICE NUMBER.
Scale Data Object
-
massArray - length 2
The first element represents the mass returned by the scale in micrograms. If the scale has been unable to calucate a weight, this element is
null. This most commonly happens when scales display a negative weight. Although many scales can display negative weights on their built-in displays, they are often unable to return negative weight readings over their USB interfaces.The second element represents the resolution of the scale in micrograms, where this is known, or
nullotherwise.For example, a reading of 125g with a resolution of 5g would be represented as
[125000000, 5000000]. -
computerIdInteger
The computer id.
-
vendorText
String description of the vendor or manufacturer of the scales device.
-
vendorIdInteger
The USB device vendor id. See here for a detailed description and see here for an up-to-date list of vendor and product ids.
-
productIdInteger
The USB device product id. See here for a detailed description and see here for an up-to-date list of vendor and product ids.
-
portText
A string representing the port to which the scale is connected, e.g. "USB1" or "COM0".
-
deviceNameText
A string identifier for the scale. This is usually the scale's manufacturer and description, unless it has been renamed in the PrintNode Client.
-
deviceNumInteger
If more than one scale with the same deviceName is connected to a computer, they will be assigned different deviceNum properties. This makes it possible to distinguish between them.
deviceNum values start at 0 and when a scale is connected to a computer it is assigned the smallest unused deviceNum value for scales with the same deviceName. For example, if two scales with different deviceNames are connected they will both have deviceNum 0. If two scales with the same deviceName are connected they will be assigned deviceNums of 0 and 1. The scale which was connected first gets deviceNum 0. -
countInteger
Reserved for future use. Currently
null. -
measurementObject
Scales can usually display their readings in imperial or metric units. The keys in this object represent the units shown on the scale's built-in display at the time of measurement. Supported units are:
g,kg,lbandoz. The value for each key is the reading in billionths of the corresponding unit. This information makes it easy to determine the reading being displayed on the scale itself. In terms of measurement, it provides the same information as themassproperty. Use whichever one you find more convenient.For example, display values of "1.2 kg", "1200g" or "2lb 10.32oz" would result in
measurementvalues of{"kg":1200000000},{"g": 1200000000000}and{"lb": 2000000000, "oz": 10320000000}respectively, but in all three cases the first element of themassarray would be1200000000. -
clientReportedCreateTimestampDateTime
The time as reported by the computer the scale is attached to at the time of generation of the scale data.
-
ntpOffsetInteger
Reserved for future use. Currently
null. -
ageOfDataInteger
The length of time for which the scale data has been stored at PrintNode in milliseconds. When receiving data over a websocket, it is delivered as soon as it is available, so this will be low – expect values from 3ms to 10ms. For the standard HTTP endpoints this will normally be much larger, although scale data is deleted after 45 seconds.
Getting All Scales for a Computer
GET/computer/COMPUTER ID/scales
Example Request cURL
Response
The response is an array of the most recent
scale data objects produced by this computer. If there are no
scales attached to the computer, the response is an empty
array. Provided COMPUTER ID is a positive integer this
method will always return HTTP 200 OK, even if
COMPUTER ID does not correspond to a computer
controlled by your account.
Filtering by Device Name
GET/computer/COMPUTER ID/scales/DEVICE NAME
Example Request cURL
Response
The response is an array of the most recent scale data objects produced by scales with device name DEVICE NAME attached to this computer. If there are no such scales attached to the computer, the response is an empty array.
Filtering by Device Name and Number
GET/computer/COMPUTER ID/scale/DEVICE NAME/DEVICE NUMBER
Note that the /scale/ part of this endpoint is
not pluralised.
Example Request cURL
Response
If there is a scale with device name DEVICE NAME
and device number DEVICE NUMBER attached to
this computer and it produced a scale data object in the last 45 seconds,
this endpoint returns the the most recent such object. Otherwise
this endpoint returns HTTP 404 Not Found.
Example Request cURL
Response
Websockets
The Best Way to Access a USB Scale From a Browser
There is a comprehensive Websocket API which covers all the scales functionality. This is the best way of accessing scales data in a browser and will provide a really fast user experience.
Everything is RFC 6455-compliant, i.e. it will work with your
browser's window.Websocket JavaScript object.
You can check browser compatibility here.
You will need to use the PrintNode JavaScript client, which is a tiny, zero-dependency JavaScript library. There are lots of examples and documentation available in the GitHub repository.
Developing and Testing the Scales API
PUT/scale
You may not have access to a physical scale during development,
so for convenience our server implements a virtual scale with the device number 0 and device name
PrintNode Test Scale, connected to computer 0.
Sending an API call to the above endpoint simulates a single measurement from this scale, which will be available in the API for 45 seconds, just like a real measurement. During this time you can query it using all scale-related endpoints. It will also be published to subscribed websockets.
Webhooks
The following terminology is specific to webhooks:
- A webhook is a setting which causes the PrintNode Server to attempt to notify an HTTP server when certain events occur.
- A target is an HTTP server which a webhook has been configured to notify.
- An event is an instance of a webhook being triggered, for example because a computer connected to PrintNode. An event has a payload, which is the data that will be sent to the webhook's target.
- A successful request is an HTTP request from PrintNode to a target which results in a response with a 2xx HTTP status code and the X-PrintNode-Webhook-Status response header set to OK.
- A failed request is an HTTP request from PrintNode to a target which is not a successful request.
A webhook has the following properties:
| Property | Description |
|---|---|
| url | The URL of the webhook's target. |
| secret | A string which will be sent to the target in each request. This allows you to verify that a message comes from PrintNode. |
| messages | An array of strings which represent the message types that should trigger the webhook. If this array contains *, the webhook will be triggered by every message type and the array must not contain any other strings. Otherwise, the webhook will be triggered by any message whose type is one of the strings in this array.
Supported message types are:
More message types will be added in the future. |
Newly created accounts have no webhooks. An account may have at most five webhooks at any point in time.
When an event occurs, it is queued up until it is due to be sent in an HTTP request to its target. The time at which a message is due is determined as follows:
- If no HTTP request has been made to the target, the message is due immediately.
- If the last HTTP request to the target was successful, the message is due immediately.
- If the last HTTP request to the target was not successful, the message is due in five seconds.
Queued events are not affected by changes to the webhooks that generated them. Deleting a webhook with queued events will not delete the events. Changing the URL of a webhook with queued events will not cause those events to be sent to the new URL.
When a failed request occurs, each event associated with that request will be re-added to the queue, unless it has already been retried, in which case it will be dropped.
An HTTP request to a target will deliver all the due events for that target. The request body is in JSON and is an array of objects that follow this pattern:
| Attribute | Type | |
|---|---|---|
| type | String | Currently supported types are computer state and print job state. More message types will be added in the future. |
| accountId | Integer | The id of the account which generated the event. |
| controllingAccountId | Integer | The id of the controlling account of the account which generated the event. An account's controlling account is itself if it is a Single Account or an Integrator Account, and its parent if it is a Child Account. |
| createdAt | DateTime | The time at which the webhook event was created. |
For a computer state message, data looks like this:
For a print job state message, data looks like this:
Viewing Webhooks
GET/webhooksExample Request cURL
Response
The response is an array of objects, one per webhook.
url, secret and messages are described above.
webhookId is a system-generated integer id which identifies the webhook. The other fields each show measures of the following qualities:
- receivedEvents – the number of times the webhook has been triggered.
- droppedEvents – the number of times the webhook has given up on sending an event's payload because it has been retried too many times.
- successfulRequests – the number of successful HTTP requests that have been sent.
- failedRequests – the number of failed HTTP requests that have been sent.
counts shows straight counts. exp7d shows exponential decay counts on a seven-day timescale. exp1d shows exponential decay counts on a one-day timescale. exp1h shows exponential decay counts on a one-hour timescale. exp5m shows exponential decay counts on a five-minute timescale.
Creating Webhooks
POST/webhook| Attribute | Type | Is Required | Specification |
|---|---|---|---|
| url | String | Yes | The URL of the webhook's target. |
| secret | String | Yes | A string which will be sent to the target in each request. This allows you to verify that a message comes from PrintNode. |
| messages | String | Yes | An array of strings which represent the message types that should trigger the webhook. If this array contains *, the webhook will be triggered by every message type and the array must not contain any other strings. Otherwise, the webhook will be triggered by any message whose type is one of the strings in this array.
Supported message types are:
More message types will be added in the future. |
Example Request cURL
Response
The response is the same as the response to GET/webhooks after changes have been made.
Modifying Webhooks
PATCH/webhook/WEBHOOK IDA webhook can be modified using PATCH /webhook/WEBHOOK ID, where WEBHOOK ID is the integer id of the webhook.
All fields in the request body are the same as POST/webhook and are all optional.
The response is the same as the response to GET/webhooks after changes have been made.
The webhook modification and response are not atomic, i.e. the response may reflect other changes made concurrently.
Example Request cURL
Response
Deleting Webhooks
DELETE/webhook/WEBHOOK IDA webhook can be deleted using DELETE /webhook/WEBHOOK ID, where WEBHOOK ID is the integer id of the webhook.
The response is the same as the response to GET/webhooks after changes have been made.
The webhook deletion and response are not atomic, i.e. the response may reflect other changes made concurrently.
Example Request cURL
Response
Account Management
If you are integrating PrintNode into your application, you might want to programmatically create and manage separate PrintNode Accounts for your customers and end-users.
PrintNode provides this functionality through Integrator Accounts. An Integrator Account is a PrintNode Account with the ability to create sub-accounts called Child Accounts. Child Accounts are separate from each other and have their own credentials but are under the control of the Integrator Account which created them.
To enable this feature, upgrade your account to an Integrator Account here.
Creating Child Accounts
POST/account| Attribute | Type | Is Required? | Specification |
|---|---|---|---|
| Account[firstname] | string | Yes | DEPRECATED. Although this field is required, it will be removed from the API soon. We strongly recommend that you set this field to - (the API will not accept an empty string) and use
Account[creatorRef] (described below) to identify the account. |
| Account[lastname] | string | Yes | DEPRECATED. Although this field is required, it will be removed from the API soon. We strongly recommend that you set this field to - (the API will not accept an empty string) and use
Account[creatorRef] (described below) to identify the account. |
| Account[email] | string | Yes | A contact email address for your customer. This email is for actions like
account password resets, informing customers of new versions of the
PrintNode Client, etc. Other than in the above cases, we will never contact your customers unless agreed in advance with you. In particular, we will never contact your customers regarding marketing or promotions and we never share data of any kind with any third party. |
| Account[password] | string | Yes | The password must be at least eight bytes long. In line with current best practices regarding password strength, we do not impose any other complexity requirements, such as inclusion of numbers and symbols. |
| Account[creatorRef] | string | No | A unique reference which you can use as a method to identify an account. |
| ApiKeys[] | Array[String] | No | An array of API Key names. When the account is created, an API key will be generated
for each name in this array. Key names must be at most 16 bytes long. At most 10 key names can be supplied. |
| Tags[] | Object | No | An object, the keys of which are tag names and the values of which are corresponding tag values. These tags will be applied to the newly created account. Tag values must be at most 1024 bytes long. |
Example Request cURL
Response
Modifying Child Accounts
To update a Child Account's properties, use
PATCH/account. To
identify
the account you wish to modify, use one of the
X-Child-Account-By-* headers.
You can modify the following properties:
firstname,
lastname,
email,
password and
creatorRef. They are all optional.
This endpoint provides the same response as
GET/whoami, showing the updates which have been made.
Example Request cURL
Response
Suspending and Activating Child Accounts
An Integrator Account may suspend a Child Account
by making a request to PUT/account/state with
an X-Child-Account-By-* header
identifying
the Child Account to be suspended. The request body should be set to
"suspended".
If the Child Account is suspended,
an Integrator Account may activate it by making a request to the same endpoint with the
request body set to "active".
An Integrator Account may check a Child Account's current state
by making a request to GET/account/state with
an X-Child-Account-By-* header
identifying
the Child Account. The response will be either "active"
or "suspended".
Example Request cURL
Response
Deleting Child Accounts
An Integrator Account may delete a Child Account
by making a request to DELETE/account with
an X-Child-Account-By-* header
identifying
the Child Account to be deleted.
Example Request cURL
Response
An Integrator Account can make an API request as if it were being performed by one of its Child Accounts by including a header which identifies the Child Account. The Child Account can be uniquely identified by its account id, its email or its creatorRef.
The headers which correspond to these identifiers are as follows.
| Identifier | Header Name |
|---|---|
| id | X-Child-Account-By-Id |
| X-Child-Account-By-Email | |
| creatorRef | X-Child-Account-By-CreatorRef |
Only one header is required.
For example, to perform an API request as the Child Account
with account id 123, set the X-Child-Account-By-Id
header's value to 123.
If an API request using an
X-Child-Account-By-* header succeeds,
it will respond with two information headers as follows:
| Header | Description |
|---|---|
X-Child-Account-By-* |
This specifies the strategy the server is using to identify the Child Account and is useful for debugging authentication problems. |
X-Authorized-As |
This specifies the Integrator Account id. |
The X-Account
response header is returned as usual and gives the account id of the
Child Account. Submitting an X-Child-Account-By-*
header which does not specify a valid Child Account will return
HTTP 401 Unauthorized.
Example Request cURL
Response
Tagging
You can attach metadata to a PrintNode Account using tags. A tag has a name and an associated value.
| Name | String. Max length 64. Alphanumeric, dot, dash and underscore characters only. |
| Value | String. Max length 1024. |
To create or update a tag make a request to
POST/account/tag/NAME.
Example Request cURL
Response
To get a tag's value make a request to
GET/account/tag/NAME.
Example Request cURL
Response
To delete a tag make a request to
DELETE/account/tag/NAME.
Example Request cURL
Response
API Keys
You can get, create or delete Child Account API Keys
using /account/apikey/DESCRIPTION.
Each API Key is identified by a unique name. Replace DESCRIPTION with the name of the API Key you wish to affect.
To create an API Key make a request to
POST/account/apikey/DESCRIPTION.
Example Request cURL
Response
To get an API Key make a request to
GET/account/apikey/DESCRIPTION.
Example Request cURL
Response
To delete an API Key make a request to
DELETE/account/apikey/DESCRIPTION.
Example Request cURL
Response
You can perform these actions for your own Account in our web app.
Delegated Client Authentication
If you have a custom-branded version of the PrintNode Client it can support third-party authentication systems. If you implement support for this, your users can securely authenticate and identify themselves to PrintNode using credentials which are stored and managed in your existing authentication system. For example, if your users normally authenticate to your Active Directory, they can use those same credentials to authenticate to PrintNode. Note that their Active Directory credentials are not sent to PrintNode.
This can be useful in situations where PrintNode is being used as a component in another system which already provides authentication and identification services. This improves your end-user experience (one fewer password to remember and manage) and provides a really seamless way to integrate with PrintNode.
How Does it Work?
The first time you install and run a PrintNode Client it asks for a username and password. The username and password are used to request a Client Key. A Client Key is a 47-character string and is conceptually similar to an API Key. It is used by a client to authenticate and identify all of its communications with PrintNode.
When using Delegated Client Authentication, the client
requests a Client Key not from PrintNode but from an API endpoint which you have implemented.
Your server checks the username and password provided by the client
(for example, against your Active Directory implementation).
If the username and password are valid, your server requests a Client Key from the PrintNode API
and returns this to the client. If the credentials are
invalid, your server returns HTTP 401 Unauthorized to the client.
In either case, the account credentials never leave your network, are never seen by PrintNode and are not retained or recorded by the PrintNode Client.
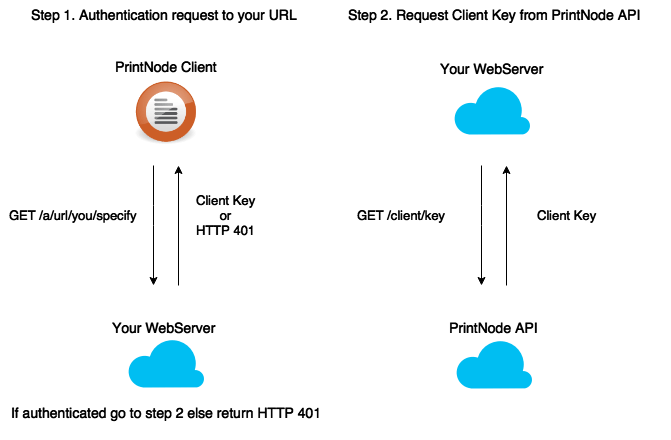
The following are required:
- You need to implement an HTTP endpoint to a specification. This is your authentication URL.
- PrintNode needs to release a custom-branded version of the client with your authentication URL embedded.
- You need to be able to request a Client Key for a Child Account.
Authentication URL Specification
Request
Your authentication URL must respond to a
HTTPS GET request. The username and password will be supplied using
HTTP Basic authentication.
The URL can be anything you choose as long as we can
encode (and you can decode) the following parameters:
- A client identifier. This is a version 4 UUID.
- A version number.
- An edition name.
For example:
GEThttps://api.printnode.com/client/key/a6860624-3838-4efd-b918-f4de765cf192?version=4.7.1&edition=printnode
Response
The requirements for the response are as follows:
- The
Content-Typemust beapplication/json. - If the response is HTTP
200 OK, the response body should be the Client Key which your server obtained from PrintNode, JSON-encoded. - If the response is HTTP
401 Unauthorized, the response should be a JSON object with two keys:codeandmessage. The value ofcodeshould beUnauthorized. The value ofmessageis up to you. Note thatmessagewill be displayed to the end-user.
A Useful Tip
When you use Delegated Client Authentication you do not need to manually create PrintNode Accounts for your end-users in advance. You can create accounts on-the-fly when your users attempt to authenticate. In your Delegated Client Authentication endpoint simply add an API request to PrintNode which checks whether a Child Account exists for that user. If not, create it and then proceed as normal.
Getting a Client Key From PrintNode
GET/client/key/UUID?edition=EDITION&version=VERSION
UUID, EDITION and VERSION are the parameters passed by the PrintNode Client to your Delegated Client Authentication endpoint.
Example Request cURL
Response
Managing Client Downloads
The PrintNode Client is actively developed and we release new versions with new features and bugfixes regularly. If we have provided you with a custom-branded client, it will receive these updates too. The latest version will be available at:
https://app.printnode.com/download/client/EDITION NAME/OPERATING SYSTEM
Valid values for OPERATING SYSTEM are
osx and windows.
EDITION NAME is a string which you may choose when we first provide
you a custom-branded client. Typically this is the name of your organization
or the application into which you are integrating PrintNode.
We strongly recommend that your users download the client directly from PrintNode using this URL. Hosting a custom-branded PrintNode Client yourself has two significant disadvantages:
- The client can only check for available updates from the PrintNode website. It cannot detect when an update is published on your own website.
- If we detect a serious bug in a client version, we can immediately prevent distribution of that version by pulling it from our website. Obviously, we cannot prevent distribution of a client which is hosted elsewhere.
Most customers are happy to automatically track the releases of the standard PrintNode Client but you may have additional QA requirements or you might wish to pin your customers to a certain version. If this is the case, no problem – the following API endpoints allow you to control which client download is presented for your edition.
Getting The Latest Client
Use GET/download/clients/OPERATING SYSTEM
to fetch information about the latest version of the client
available for an operating system. Valid values for OPERATING SYSTEM
are osx and windows.
Example Request cURL
Response
Getting All Clients
You can get a list of all client versions supported for your account using the following endpoints:
GET/download/clients
GET/download/clients/DOWNLOAD ID SET
Example Request cURL
Response
Enabling and Disabling Specific Clients
The generic download endpoint at
https://app.printnode.com/download/client/EDITION NAME/OPERATING SYSTEM
and GET/download/clients/OPERATING SYSTEM
fetch information about the highest versioned
client which is enabled for a given operating system.
PrintNode allows you to control which client version is presented
at these enpoints by enabling or disabling individual client downloads.
To enable or disable one or more downloads, make a request to
PATCH/download/clients/DOWNLOAD ID SET.
The request body should be
{"enabled": true} or {"enabled": false}.
DOWNLOAD ID SET is the set of ids of the client downloads
you wish to affect.
Example Request cURL
Response
Miscellaneous
Ping
GET/ping
If you want to test the accessibility of the PrintNode API,
make a request to GET/ping. No authentication is required.
If the PrintNode API is available it will respond with HTTP 200 OK.
Example Request cURL
Response
No Operation
GET/noop
If you want to check your credentials but do nothing else
you can make a request to GET/noop. If your
credentials are valid, the PrintNode API will return HTTP 200 OK
and the response body will be the JSON-encoded Request-Id. If your credentials
are invalid, you will receive HTTP 401 Unauthorized.
